Graph Upgrade Overview and Compatibility
Overview
JupiterOne is upgrading the primary data stores used to process J1QL queries. The project is intended to improve query performance and reduce the time in which the latest data is available to query.
As part of this upgrade user will get access to an improved query experience, with a more responsive and configurable results page.
The upgrade involves some changes in behavior of queries and the results returned to the user. JupiterOne believes that each of these changes is towards more correct results.
New Search Experience
As part of the graph upgrade program JupiterOne is introducing an improved search experience and results table. Users will be able to get more value and a better experience when searching data in JupiterOne.
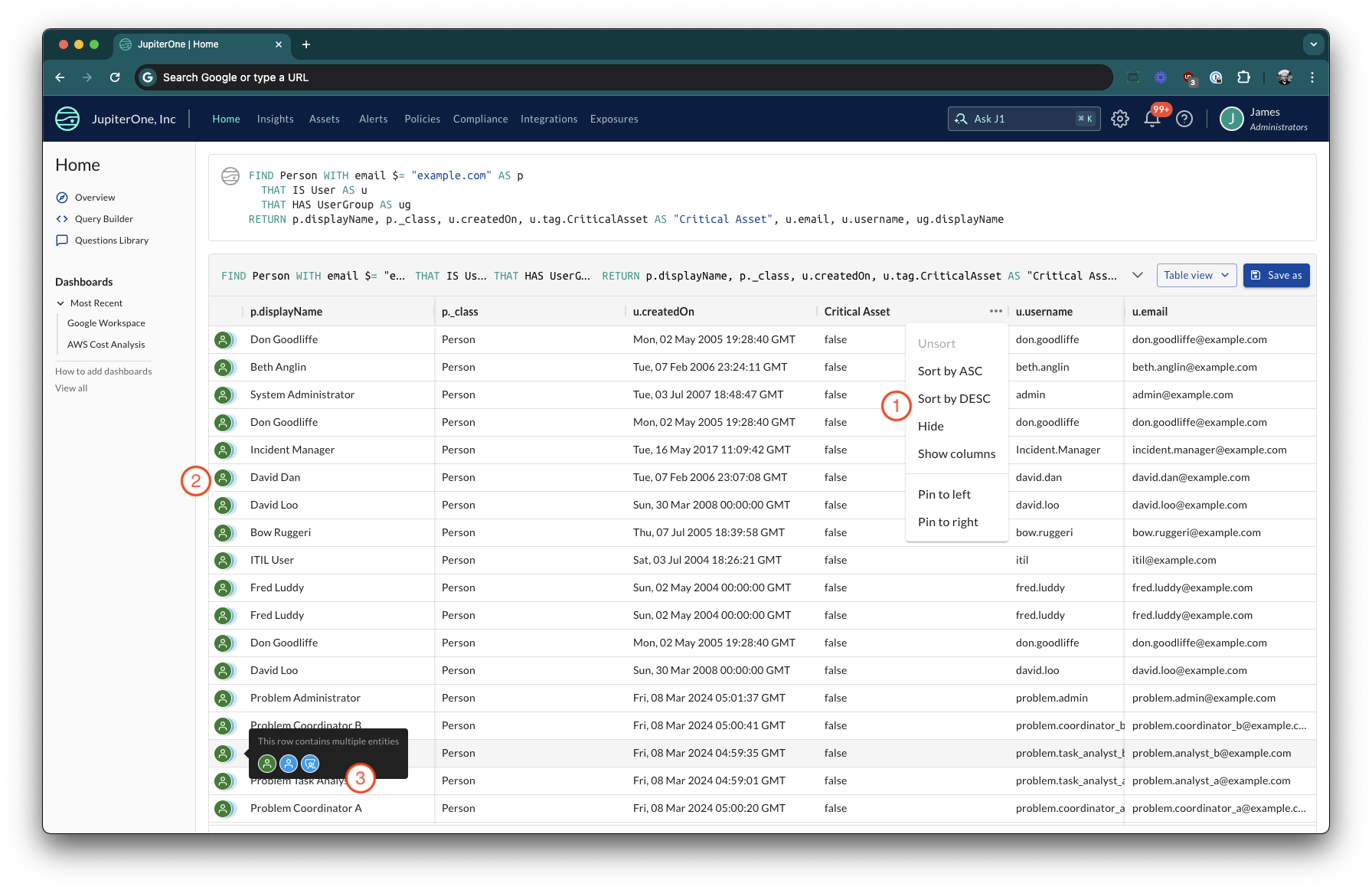
Increased Results Limits
The table will now show up to 250 results per page, with on-demand loading of additional pages. This allows the system to return the first page of query results to a user much faster in most cases.
The results table produces either a total row count, or an estimate for very large result sets. As you paginate through the pages the estimate becomes more refined, or becomes the absolute value.
Faster, more stable experience
The table component has been rebuilt to only render the section of the table visible to the user. This has made scrolling vertically and horizontally though large tables of results much more performant on the browser.
Column resizing, reordering, and left/right pinning
Columns can now be drag and dropped into a new ordering, with the ability to pin one or more columns to either the left or right side of the table. This makes understanding the data in the table much easier and more intuitive (1).
Quick column selection, including in Insights table widgets
Users can now much more quickly select which columns to show, including a column name search filter. Also includes the quick option to "Hide" a column without having to redo column selection.
Colors and Icons for Classes of Assets
Providing a more consistent and intuitive experience for users (2).
Stacked Icons for Graph Queries
When returning a graph query (i.e. a query with a traversal) and returning columns from multiple elements the icons to the left of the table show a stacked representation of the entity types (2), with a tool tip (3).
Query Compatibility and Results
The compatibility changes have been grouped into MAJOR, MEDIUM, and MINOR categories.
- MAJOR: Indicates a change in behavior that may significantly change query results
- MEDIUM: Covers changes where query results may change slightly, or previously invalid queries may now be rejected
- MINOR: Typically more style based changes, but might introduce incompatibility with downstream systems
API Pagination / Query Result Ordering MAJOR
In the legacy query service the same query on unchanged data, in some cases, would produce results with a stable order. This was not true for all queries, and should not be relied upon.
The new query engine produces results in any order and will frequently do so for the same query against unchanged data.
Paginating through query results using a cursor and VariableResultSize flag is always guaranteed to eventually return all results for a query.
For more details on this topic, and changes customers will need to make by 1st September 2024 please see the extended notes.
This change was originally classified as a MINOR change, but the impact has proven to be greater than expected. Customers using inappropriate API query calls are being proactively contacted to update their usage.
All JupiterOne provided clients / SDKs have been updated to use the appropriate options, please check you are using the latest clients.
Unwinding of Arrays MAJOR
Previously JupiterOne would "unwind" rows where the returned values contained arrays of values. This would introduce more results than expected in a lot of cases. The results are no longer unwound in this fashion.
- This may reduce the number of results in queries and alerts. The new number of rows better reflects the actual number of assets returned in your query
- Aggregations on properties with arrays no longer duplicates counts across rows
Using the following query as an example, where we have 461 aws_instances in the system:
FIND aws_instance AS i
RETURN COUNT(i) AS "Instance Count", i._integrationClass AS "Integration Class"
The legacy query service would return a table like so:
+----------------+---------------------+
| Instance Count | Integration Class |
|----------------|---------------------|
| 461 | CSP |
| 461 | Infrastructure |
+----------------+---------------------+
The upgraded query service will return this table:
+----------------+---------------------+
| Instance Count | Integration Class |
|----------------|---------------------|
| 461 | CSP, Infrastructure |
+----------------+---------------------+
The rationale here is that the sum of the aggregates should reflect the total number of assets, not the count of each individual property. This was particularly confusing in the legacy system where properties with array values were not clearly identified to the user and the number of rows, or aggregation results, did not match the total number of assets.
The way you search against these properties is not changed. The following query still returns all the results:
FIND aws_instance WITH _integrationClass = "CSP" AS i
RETURN COUNT(i) AS "Instance Count", i._integrationClass AS "Integration Class"
ORDER BY on returned columns only MEDIUM
Previously it was possible to order results by any property, even if that property was not in the returned columns. In the upgraded query system it is only possible to ORDER BY on properties that are returned in the results.
This query will still produce results, but the ordering will not be applied:
FIND aws_instance AS i
RETURN i.displayName, i.arn
ORDER BY i.accountId
The query should be written as:
FIND aws_instance AS i
RETURN i.displayName, i.arn, i.accountId
ORDER BY i.accountId
Aliasing a Negated Traversal MEDIUM
It was previously possible to alias a negated (do not match) traversal. This was confusing to users as the alias is to something that "does not exist". The results of such an alias, when included in a RETURN or aggregation, were undefined.
The following query will now produce an error. Note the negated traversal !RELATES:
FIND aws_instance AS i
THAT !RELATES TO DataStore AS ds
RETURN i.displayName, i.arn, ds.displayName, ds.arn
The error returned is Could not find node, relationship, or variable with identifier ds
Less De-duplication in Optional Traversals MEDIUM
Previously, optional traversals would de-duplicate traversal paths based on a collection of entities that were previously traversed. This would at times remove results that should have been included.
After the upgrade the system will not de-duplicate these matching paths. This is a more correct representation of the relationships in the graph as it shows all possible paths, although it is possible there will be more duplicated data in the results.
These effects can also be observed across multiple pages of results, they will not necessarily appear adjacent to each other in the table output.
The effect of this change can be reduced by including the UNIQUE keyword in queries.
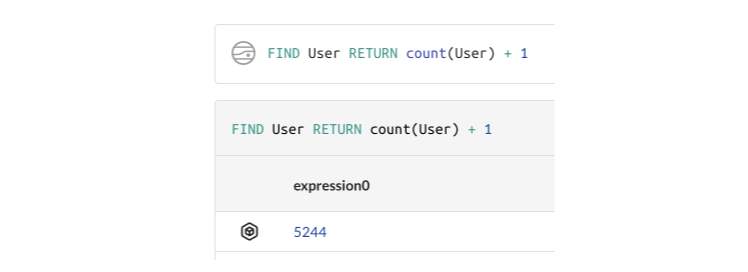
Default Expression Names now more descriptive MEDIUM
Using an expression (aggregation, math operator, etc) in a RETURN without an AS alias would historically generate names such as expression0. This was unhelpful as it did not clearly indicate the source of the data. As part of the graph upgrade the expression names are now derived from the expression itself, when not aliased.
The legacy behavior:
New behavior:
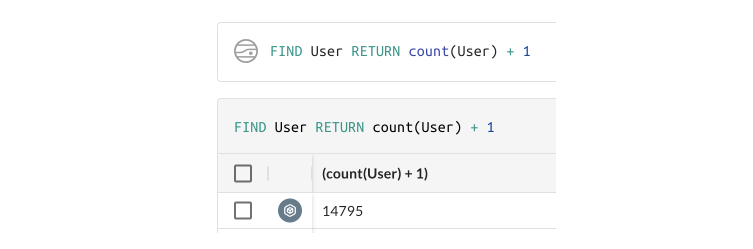
This change may have an impact on any automation that expects the old expressionN format of un-aliased expressions.
RBAC Policy Filters no longer modify returned properties MEDIUM
It is possible in JupiterOne Enterprise RBAC access policies to filter what assets a user can query based on properties of those assets (e.g. limit a group of users to a specific AWS account by filtering on accountId), this is not being changed.
Additionally the system would strip non-matching property values from the returned entities based on these policies, the new system no longer does this.
Example: A user has an access filter that limits access to only entities with _class = Device. If this user searches in JupiterOne and we return an entity with _class = ['Device', 'Host'] historically the system would strip out the filtered property value, so the user would see the entity as having _class = ['Device'].
Having reviewed this feature it was determined this offered no meaningful security to the system and caused significant confusion when comparing entities between users with different RBAC policies.
Full Text Search Tokenization MEDIUM
Previously full text searches would tokenize the search string based on word boundaries, e.g: searching for "Keith Packard" would match an entity containing keith.packard@example.com. Alternatively, searching for "keith packard" would match Keith Packard.
The new query full text search functionality only supports case-insensitive “contains” searches. For example, if you search "Keith Packard", it now returns Keith Packard, keith packard, KEITH PACKARD, etc. It will NOT match things like keith.packard@example.com or Keith-Packard.
This simplification was made as analysis of full text search behavior indicated that only literal matches were desirable, rather than tokenized matches across all properties.
For more advanced text searching it is recommended to look at the new regex functionality in J1QL.
This change may have an impact on any Insights dashboards where the dashboard filters were applied as a free text search at the beginning of the query.
Undefined Properties returned as Null MINOR
Where undefined properties were previously returned as undefined these are now returned as null. This change allows for better serialization to JSON.
The way you search against these properties is not changed. The following query syntax should continue to be used:
FIND aws_instance WITH ebsOptimized != undefined
Invalid Numeric Aggregations return 0 MINOR
Previously, J1QL would return NaN for any sum operation that included non-summable data (i.e. non-numeric strings).
J1QL will now return 0 for the aggregation.
Relationships to Self MINOR
The legacy graph implementation would filter out relationships that looped back to the same object, for example aws_security_group objects often have a relationship to themselves. In the following query in the previous implementation the query would return only instances where the source was not the same node as the target:
FIND aws_security_group AS source
THAT ALLOWS aws_security_group AS target
The upgraded query service does not remove these relationships as they can carry potentially important information.
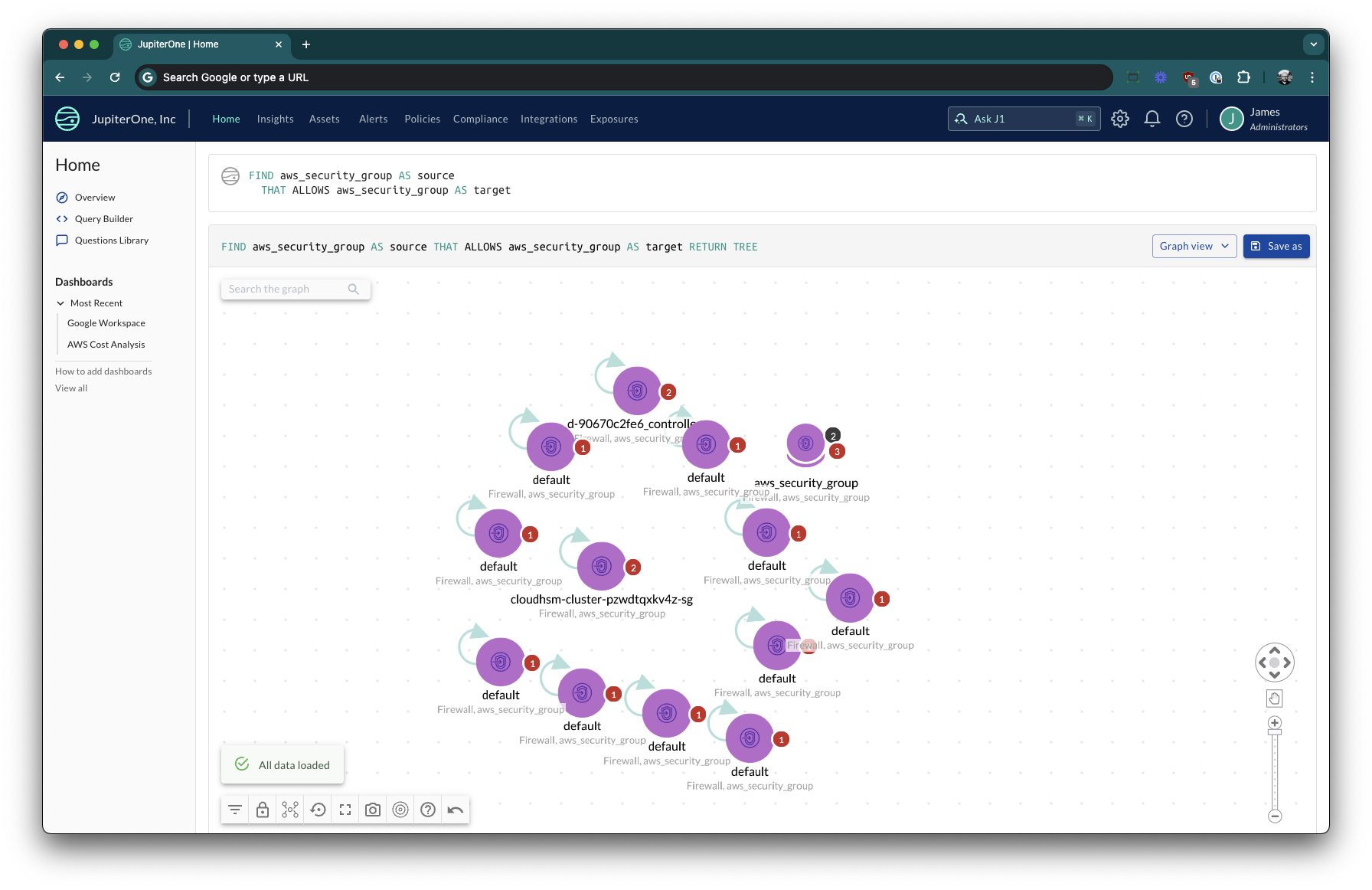
To replicate the legacy behavior it is necessary to introduce an additional check where the source and target are not the same node:
FIND aws_security_group AS source
THAT ALLOWS aws_security_group AS target
WHERE source._id != target._id
Optional Traversals De-Duplicate Short Paths MINOR
Take the following optional traversal query:
FIND Person AS p
(THAT IS User AS u)?
In the legacy implementation, a return of both the optional match and the non-optional matched rows were returned.
Examples of old results:
{ p: { <some person> }, u: undefined }
{ p: { <some person> }, u: { <some user> } }
In this case the person is the same, and both the paths were returned for a single entity.
In the new system, only the row on the optional path (when it exists) will be returned. This reduces confusion over what was found using the optional vs non-optional path.
Instead of returning both rows above the new system will only return:
{ p: { <some person> }, u: { <some user> } }
Or if the optional traversal does not match:
{ p: { <some person> }, u: undefined }
Nested Optional Traversals MINOR
The legacy system allowed for inner traversals within optional traversals like so:
FIND User
(THAT IS Person
(THAT HAS AccessKey)? )?
This capability was not documented and is no longer supported. The intention of such a query was undefined. The equivalent supported query would be:
FIND User
(THAT IS Person)?
(THAT HAS AccessKey)?
Nested Optional Traversal Negation MINOR
The legacy system allowed for inner traversals with chained negated traversals like so:
FIND User
(THAT IS Person
THAT !HAS AccessKey)?
This capability was not documented and is no longer supported. The intention of such a query was undefined.
Aliasing to non-ASCII or Empty String MINOR
J1QL previously allowed for non-ASCII or empty string literal as an alias:
FIND Person AS p
RETURN p.displayName AS ""
In the new system, empty string literals will not be allowed and all aliases must be non-zero length ASCII strings.
Empty results due to property selections filtered out MINOR
When running a J1QL query with column selectors, if all the columns selected had no values empty objects would be filtered out from query results. This meant that the number of rows would not accurately reflect the number of assets returned in the query, only those with the selected attributes.
For example, the following query would only return AWS instances that have a public IP address set, and any AWS instance without that property would be filtered from the results:
FIND aws_instance AS i
RETURN i.publicIpAddress
This was confusing because the "total" number of results would reflect the complete count of all aws_instance objects, so you may see a table or result set with 10 rows but get a count of hundreds of instances.
In the new system, empty objects will be returned. This displays more clearly what the results actually are instead of obscuring potentially important information about the structure of the returned data.
If a query relies on this behavior to filter results the property should be moved to be a filter also:
FIND aws_instance WITH publicIpAddress != undefined AS i
RETURN i.publicIpAddress
CONCAT() now concatenates arrays MINOR
The CONCAT() function, when passed two properties that were arrays, would behave more like a ZIP() function. This function now properly concatenates the arrays together.
Using the following query as an example:
FIND aws_instance AS i
RETURN CONCAT(i.privateIpAddresses, i.privateDnsName) AS privateEndpoints
In the legacy system would produce results like this:
+----------------------------------------------------------------------------------------------------------------------+
| privateEndpoints |
+----------------------------------------------------------------------------------------------------------------------+
| ["10.0.3.123ip-10-0-3-123.us-east-2.compute.internal", "10.0.3.146ip-10-0-3-123.us-east-2.compute.internal"] |
| ["10.0.3.19ip-10-0-3-54.us-east-2.compute.internal", "10.0.3.21ip-10-0-3-54.us-east-2.compute.internal"] |
| ["10.0.1.131ip-10-0-1-52.us-east-2.compute.internal", "10.0.1.212ip-10-0-1-52.us-east-2.compute.internal"] |
+----------------------------------------------------------------------------------------------------------------------+
And now produces results like this:
+----------------------------------------------------------------------------------------------------------------------+
| privateEndpoints |
+----------------------------------------------------------------------------------------------------------------------+
| ["10.0.3.123", "ip-10-0-3-123.us-east-2.compute.internal", "10.0.3.146", "ip-10-0-3-123.us-east-2.compute.internal"] |
| ["10.0.3.19", "ip-10-0-3-54.us-east-2.compute.internal", "10.0.3.21", "ip-10-0-3-54.us-east-2.compute.internal"] |
| ["10.0.1.131", "ip-10-0-1-52.us-east-2.compute.internal","10.0.1.212", "ip-10-0-1-52.us-east-2.compute.internal"] |
+----------------------------------------------------------------------------------------------------------------------+
Null no longer filtered from MERGE() MINOR
The MERGE() function will now preserve null values when merging, as this gives a more correct array length for the results.
If the null value is not desired it should be filtered in the query when possible.