Docker based Collector
The Docker-based JupiterOne Collector is designed for deployment on a dedicated Linux VM or host using Docker Engine. This guide covers requirements, installation, and management.
System Requirements
| Operating System | Any modern 64-bit systemd linux distribution should work. The JupiterOne Collector has been specifically tested against the following Operating Systems using the official Docker Engine:
|
| Container Runtime | Whilst any docker compatible container runtime should work (e.g., podman), only the official Docker engine has been tested and certified to work. See Docker installation instructions here. There are specific notes later in this document if you wish to use podman instead of Docker, see Podman Container Runtime. |
| CPU | 4 vCPU The CPU requirement is dependent on the integration workload, but 4 vCPU is a good starting point. |
| RAM | 2 GB minimum, 8 - 12 GB recommended. Most integration jobs operate with <1GB of RAM but the memory requirement will depend on the number of entities being handled. Some very large integration instances, those handling millions of entities, may require 10GB+ of available memory. |
| Networking | The Collector needs to be able to connect to JupiterOne's services at *.us.jupiterone.io or *.eu.jupiterone.io over HTTPS/443. The JupiterOne Collector host also needs connectivity to the integration target; e.g., if running an Active Directory integration, it will need connectivity to your local LDAP port of your AD servers. The container images are pulled from the GitHub package registry at ghcr.io. The container images are all signed by JupiterOne, this requires connectivity to the cosign signing service also hosted at github. |
| Storage | 50 GB available local storage. JupiterOne integrations running on the Collector do not themselves need persistent storage. Only the JupiterOne Collector itself requires persistent storage to maintain a configuration file. The Collector host should have sufficient local storage to hold logs for the various services. |
Container Runtime
We recommend using the official Docker Engine. The installation instructions depend on the host OS, and can be found here: https://docs.docker.com/engine/install/
You do not need to install Docker Desktop features. For Ubuntu you would use these instructions: https://docs.docker.com/engine/install/ubuntu/
You can confirm you have a working container runtime environment on your host machine using a test command:
sudo docker run hello-world
Which should produce the following output:
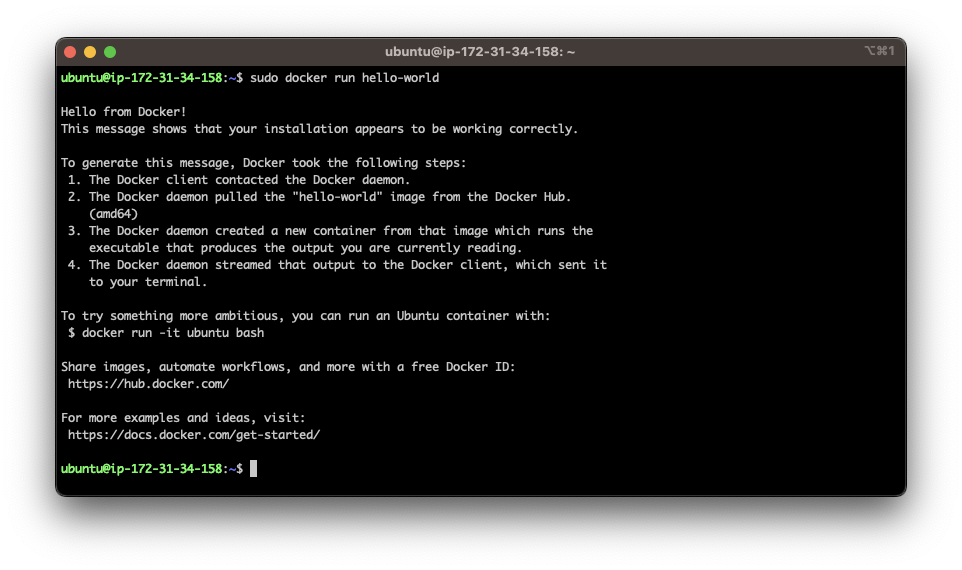
This confirms that the docker engine is running and able to pull and launch containers. At this point you are ready to deploy a collector.
Deploying a Collector
To set up a collector, you will need a JupiterOne account.
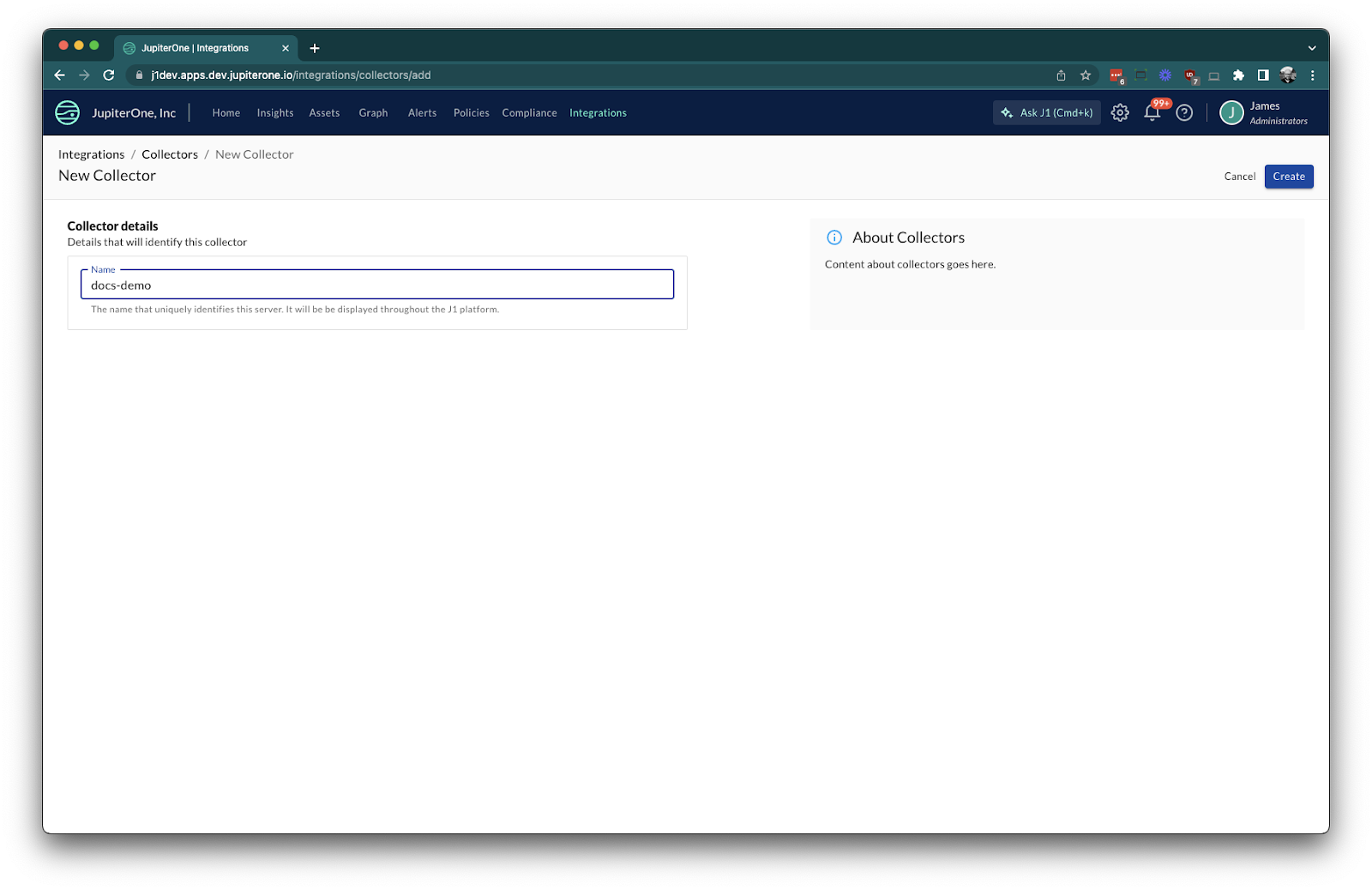
- Navigate to Integrations > Collectors, choose New collector. Provide a name for the new collector and select Create:
- Take the terminal command and run it in your new collector instance.
You may need to prefix the command with sudo depending on how your permissions are configured and your current user.
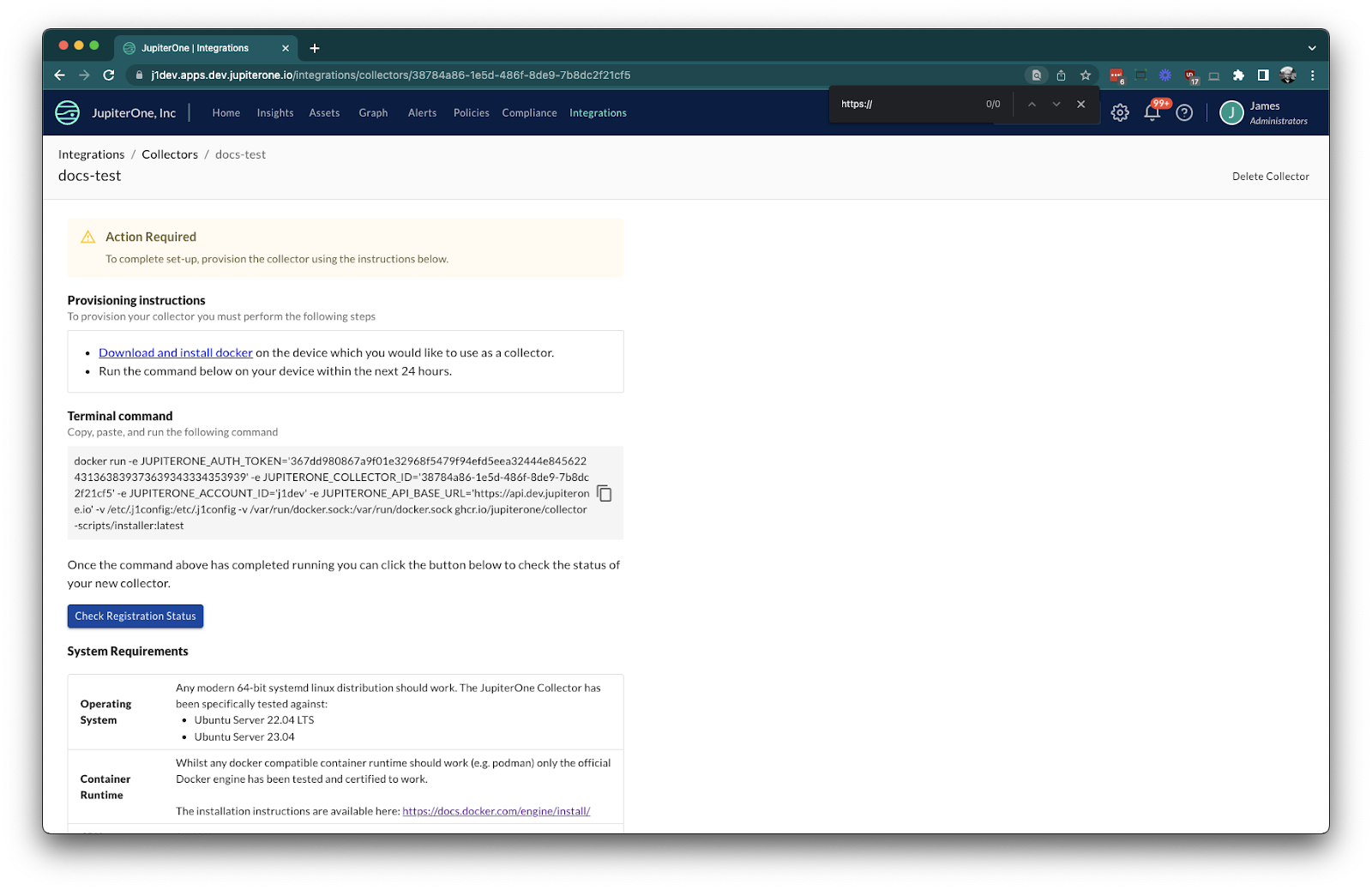
Example command:
docker run -e JUPITERONE_AUTH_TOKEN='...' -e JUPITERONE_COLLECTOR_ID='...' -e JUPITERONE_ACCOUNT_ID='...' -e JUPITERONE_API_BASE_URL='...' -v /etc/.j1config:/etc/.j1config -v /var/run/docker.sock:/var/run/docker.sock ghcr.io/jupiterone/collector-scripts/installer:latest
docker runis the command to run the installer container.-eare environment variables for authentication and configuration.-vare volume mounts for configuration and Docker socket access.
Running this command on your Collector host will kick off the process to setup the collector.
- Confirm the collector is running using
docker ps. You should see two containers running (daemon and runner):
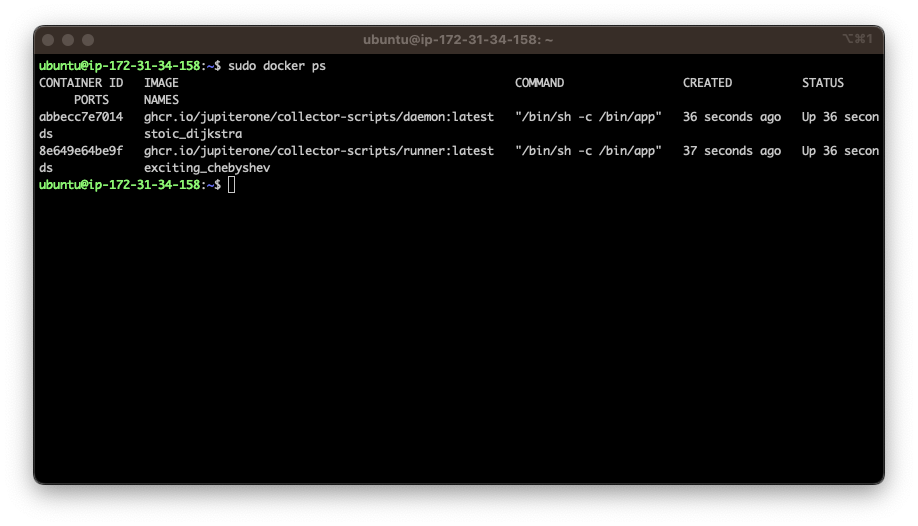
- Daemon: Manages local state, upgrades, and health checks.
- Runner: Manages the job queue and launches integration jobs.
- Examine the logs of the runner to ensure it's successfully connecting to JupiterOne:
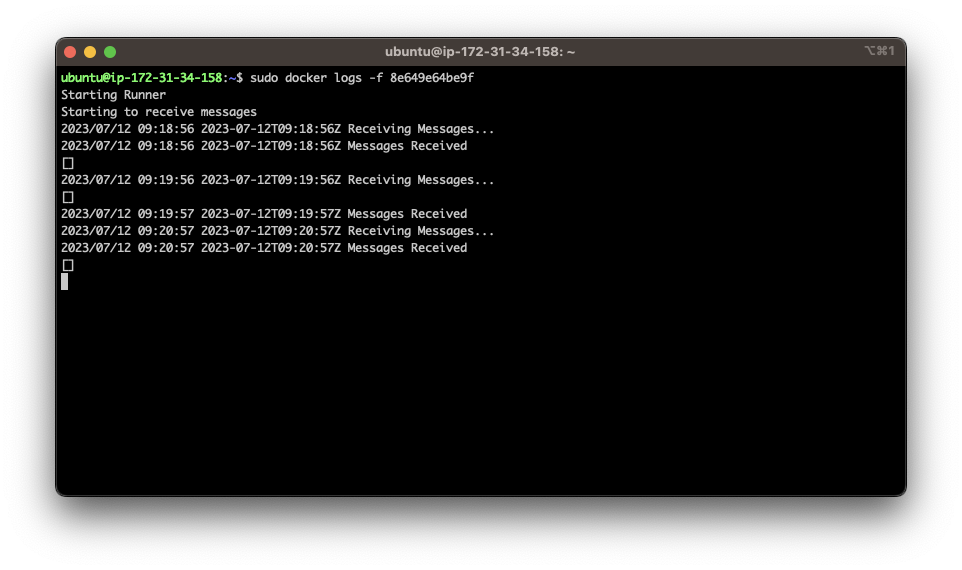
At this point the collector is set up and running. You will see the collector as "Active" in the collector overview after a few minutes:
The collector containers are running with a restart policy of "unless-stopped", so they will restart automatically on failure, and will start automatically when the container runtime (re)starts, i.e. at system reboot time.
Assigning an Integration
Assigning an integration job to a collector first requires that there are collectors registered and available. Once collectors are available, the process for defining an integration job and assigning it to a collector is straightforward.
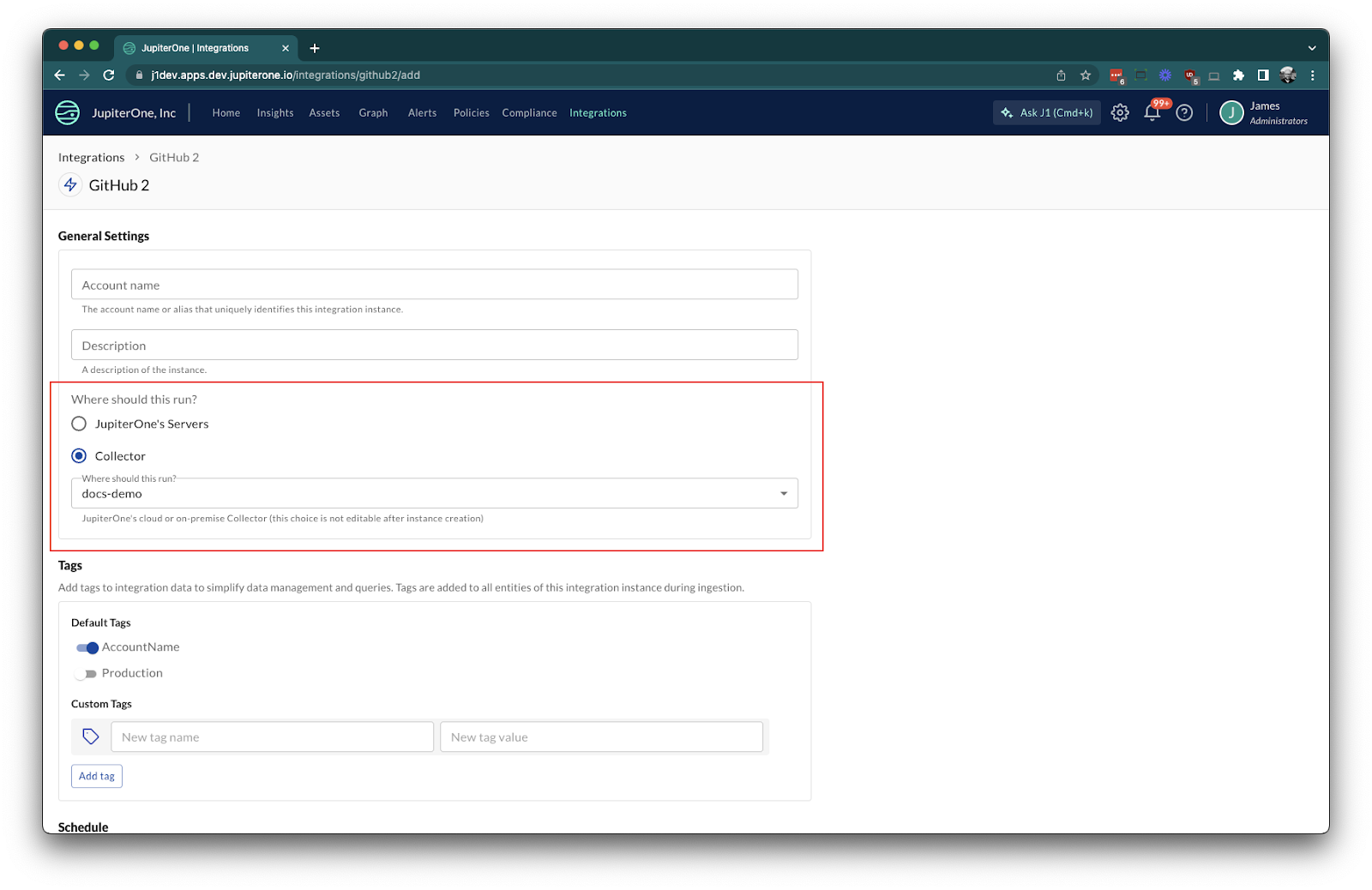
For integrations that are collector compatible, complete the integration configuration as normal. During configuration, you'll notice there's an additional option to choose where the integration should run.
Select Collector on the integration instance, and choose the corresponding collector for which you'd like the integration to run.
Podman Container Runtime
If you prefer to use podman instead of Docker, follow these steps:
- Install the
podman-dockerandpodman-remotepackages:
sudo dnf install -y podman-docker podman-remote
- Enable the podman socket:
sudo systemctl enable --now podman.socket
- Create the JupiterOne configuration directory:
sudo mkdir -p /etc/.j1config/
- Use the installer command, replacing
dockerwithpodmanand adding the--privilegedflag:
sudo podman run --privileged -e JUPITERONE_AUTH_TOKEN='...' -e JUPITERONE_COLLECTOR_ID='...' -e JUPITERONE_ACCOUNT_ID='...' -e JUPITERONE_API_BASE_URL='...' -v /etc/.j1config:/etc/.j1config -v /var/run/docker.sock:/var/run/docker.sock ghcr.io/jupiterone/collector-scripts/installer:latest
The --privileged flag is required to allow the collector to manage the container runtime when using podman. Review the security implications of running the collector with these privileges.
Removing a Collector
- Remove the collector from the JupiterOne console using the "Delete Collector" option.
- On the collector host machine, stop and remove the collector daemon and runner containers.
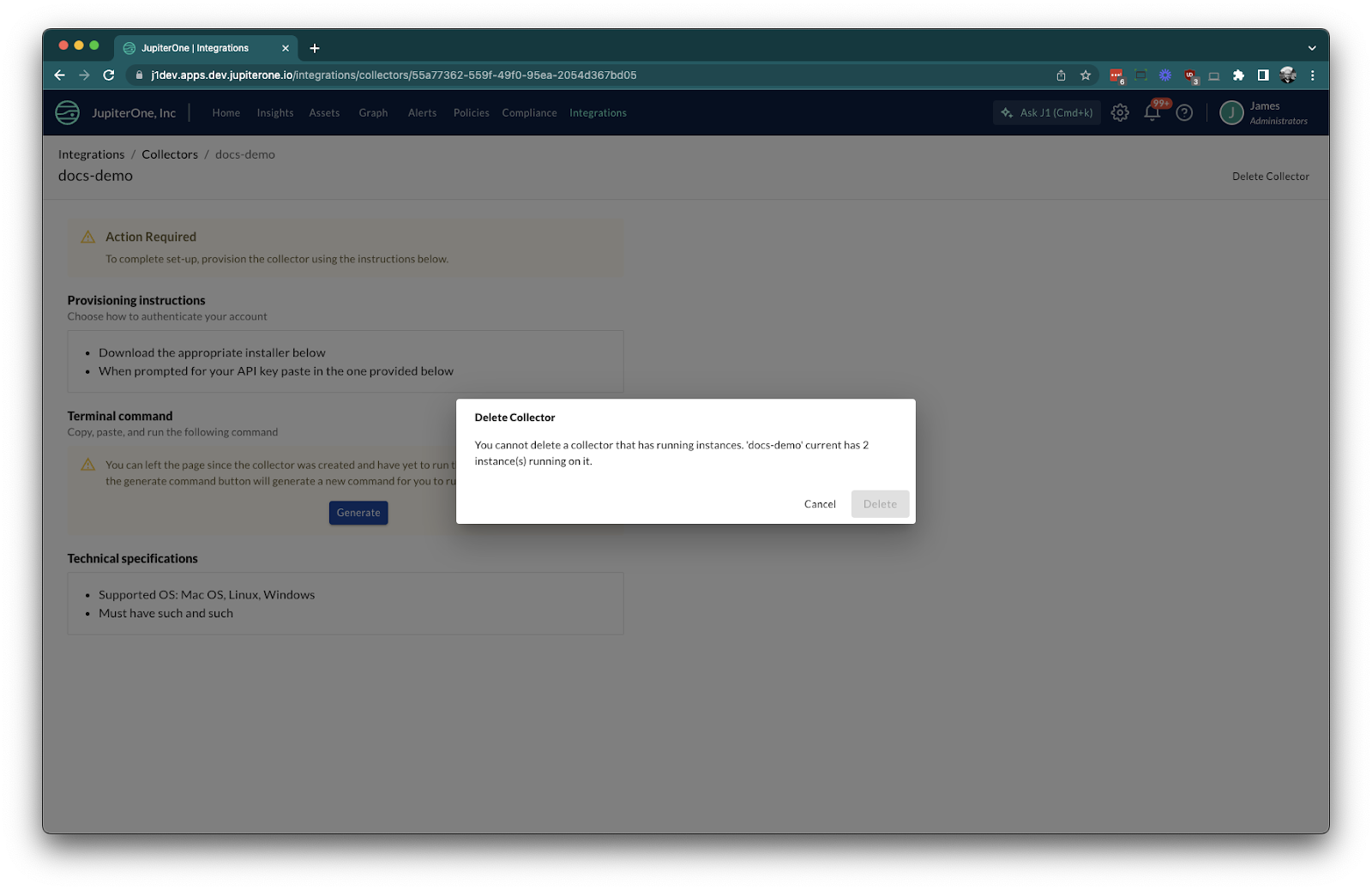
If you try deleting a collector that has integrations configured you will see a message like the following:
Known Limitations
- Unable to migrate integration jobs between collectors.
- Integration jobs may run in parallel if multiple jobs are assigned.
- Limited high availability (single node).